
Please note that nobody is informed when people leave questions on system articles. If you need help, use the forums.
How to: PhoMo
▲
7▲ 7 ▼ 0
This public article was written by [Deactivated User], and last updated on 7 May 2020, 18:49.
[comments] [history] untagged
5. PhoMo FAQ
6. PhoMo Page
7. PhoMo Rules
10. X-SAMPA to IPA
?FYI...
This article is a work in progress! Check back later in case any changes have occurred.
This article is a work in progress! Check back later in case any changes have occurred.
This is a tutorial for using CWS's Phone Modifier (PhoMo) system. It is, in effect, a compilation of the PhoMo Rules, PhoMo Examples, and PhoMo FAQ, intended to be a bit easier to follow, with more examples. We will start off with a "quick and dirty" tutorial, especially useful for people who already know how to work similar Sound Changers like SCE. Then, we'll go over Categories (a database you set up for PhoMo to interact with), how to use the PhoMo page, how to read and write PhoMo rules, and finally a lot of example rules and some tips and tricks.
What is PhoMo? It is a tool and coding languageI have been informed it is merely a 'domain-specific string-substitutor' used to apply sound changesallophonic or diachronic to words in dictionary entries, translations, etc, or to inflect/conjugate words within grammar tables. For example, you could use it to change 'p' into 'b' if it occurs between two vowels, to delete word-final /h/, or add the suffix '-na' to your verbs.
Many simple rules can be generated with the PhoMo Wizard. This can be a good place to start if you're uncertain of how PhoMo works.
If, by the time you are finished this article, you still have questions, can't puzzle out how to do what you want, or can't figure out why something's not working, head on over to the PhoMo Help Centre board thread.
!!Important!! If you have multiple languages on CWS, do not switch between them while on the PhoMo page. If you do accidentally do this, hit the [reload] button before the "Apply rules & Save Changes"; or, you can simply navigate to another page, and then come back. If you do hit "Apply rules & Save Changes" after switching languages while on the PhoMo page, your ruleset will be overwritten by the other language's set.
[top]Quick-and-Dirty Tutorial
If you're finding this section difficult to follow, skip to the in-depth explanations in later sections. All of the same information will be covered.
PhoMo rules are built in two to five parts, each separated by a forwards slash, like this: target/change/environment/exception/else. We also call these sections by the the shorter codes TRG/CHG/ENV/EXP/ELS. In short, this means: the 'target' becomes the 'change' if the 'environment' is true and the 'exception' is false, otherwise it becomes 'else.' The environment and exception can be called the 'condition' (COND) together while CHG and ELS can be paired as 'results' (RES).
Rules only require TRG and CHG. These can be accompanied by any combination of ENV, EXP, and ELS. (ELS will never actually be applied if there is no condition, though.) To skip a section, just write another /, e.g. a/b//c has an exception but no environment. Note that leaving a RES blank means "delete", not "skip."
There are two types of conditions, global and local. Global conditions include things like 'if the word contains e' or 'if the word ends in p'. Local conditions are things like 'before /i/' or 'between vowels'.
Within TRG and RES, # represents the whole word. So, #/#s suffixes 's' to the word. Global conditions use # in a similar manner, so here #s means 'if the word ends in a s.'
Local conditions use _ to represent TRG; s_ means 'after s'. Unlike global conditions, local conditions use # to mean 'the word edge' instead of 'the word.' This means that _# represents the end of the word, not the beginning.
Here are a few simple rules as examples to get you started:
| Code | Meaning | Example |
|---|---|---|
| n/m | Turn all n into m. | nanaŋ→mamaŋ |
| #/#t | Suffix -t. | aka→akat |
| p/b/V_V | Turn p into b between two V. | spapa→spaba |
| #/#t/#V | Suffix -t if word ends in V. | aka→akat; akas→akas |
| s/ʃ/_i/s_ | Turn s to ʃ before i, but not after s. | asi→aʃi; assi→assi |
| g/k/_#/g_ | Turn g to k word-finally, except after g. | tilpag→tilpak; tilpagg→tilpagg |
| #/mo#/C#//m# | Prefix mo- if word begins with C, otherwise prefix m-. | pake→mopake; ake→make |
[top]Categories
An important function of PhoMo is its ability to read Categories. Although you can technically use PhoMo without any Categories at all, they make a lot of things a lot easier.
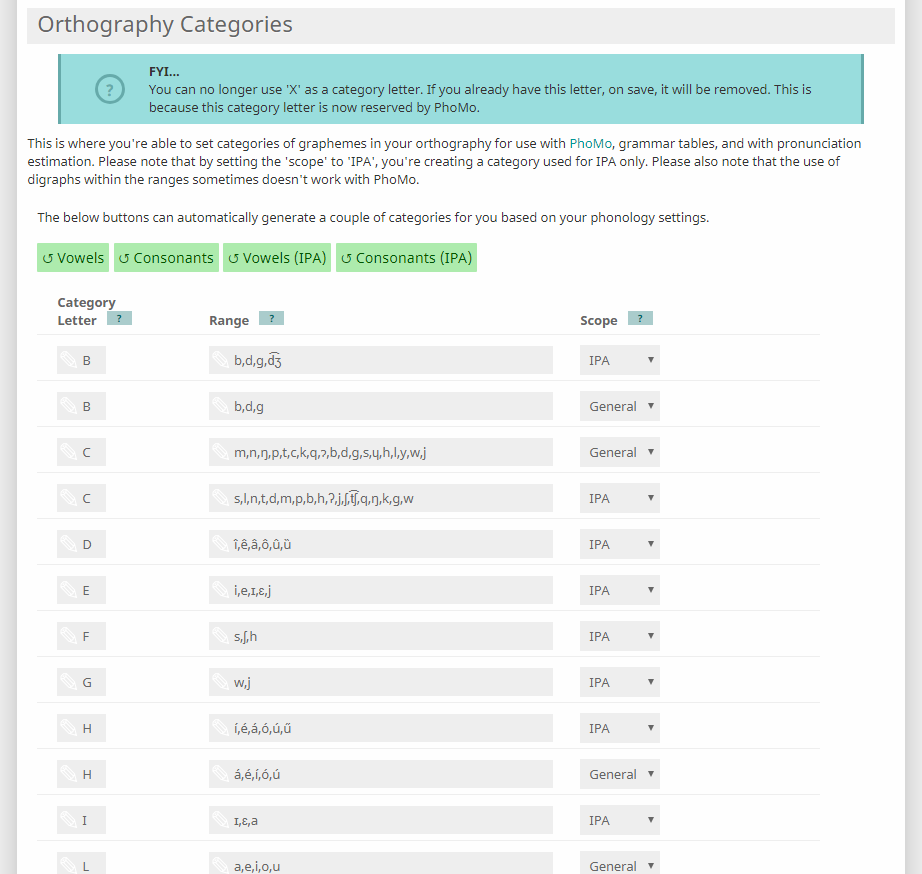
The Categories page for
 Achiyitqan.
Achiyitqan.Categories are sets of sounds that can be modified or referenced en masse by a single rule. They are language-specific, meaning each language you make can have completely different Categories.
Categories are named with a single capital letter (which can be a special character like Å), which corresponds to a list of individual phones, delimited by commas (e.g. a,å,o,ø). All Categories of the same "scope" (see below) must be unique, e.g. you cannot have two different categories labeled V for the General scope.
Members of categories should be single, lowercase letters only. You can include digraphs, but PhoMo will not read them correctly (including things like /kʷ/, /d͡ʒ/ and /a:/). There are workarounds for this, as you can see in the Tips & Tricks section near the bottom.
In sound changes, you can merge all members of a category (e.g. you could merge all nasals (N for m,n,ŋ) into [m] before /p/). You can also change its members into their counterpart (by order) in another category (e.g. changing voiceless stops (P for p,t,k) into voiced stops (B for b,d,g)). (You must make certain these are ordered correctly.)
Categories can fall under one of three Scopes. Basically, this means each of your languages can have three different sets of Categories, which are read by different parts of the site. Use the General scope to interact with your language's orthography/romanization (e.g. in Grammar Tables), the IPA scope to interact with its Phonology (e.g. pronunciation estimation), and the Test scope to just muck about in PhoMo without messing anything else up.
You can also use temporary categories by listing phones, comma-delimited, in your rules (e.g. e,a,q,l), which can be useful if you don't intend to use that 'category' more than once. (These are interpreted as the category X by the site, so you cannot use X as a category marker.)
You can automatically generate two basic categories (Consonants and Vowels — C and V) for two different scopes (IPA and General) by hitting the "↺ Vowels" (etc) buttons at the top of the Categories page. These draw from your language's Phonology, so they will not work if your Phonology is empty. They will also not work with non-standard phonological systems. (However, you can easily reproduce these categories by hand.) They will not produce any polygraphs or modified sounds (e.g. kʷ, tʃ). They do not automatically update when you add or delete sounds from your Phonology, so you will have to do this manually.
Categories can contain letters/phones that your language doesn't use, if you want. Likewise, not all letters/phones used by your language or in your PhoMo ruleset have to appear in any Category.
[top]Using the PhoMo page
This sections explains how the PhoMo page itself is set up, and what all the little buttons do.
Here is a screencap of PhoMo for a brand-new language:

And here's one for
Achiyitqan, which I've worked on rather more:
You'll note that there are a lot more options and links, including an entire additional section, in the second image. As you fill out your language on CWS, your PhoMo page will start to resemble mine more.
Here's an overview of the parts and their functions:
- Links
- Simply links you to help articles. It'll probably have more after this article is done, though ;)
- Simply links you to help articles. It'll probably have more after this article is done, though ;)
- Ruleset dropdown
- This drop-down menu lets you choose between PhoMo rulesets that you have already named and used. In the second image, the loaded ruleset is *Rewrite Rules*, which works with the site's Pronunciation Estimation feature.
- If you have no rulesets (because you've just started!), this will of course be empty.
- Once you have at least one ruleset saved, you can [delete] it, [reload] it (from the last version saved to the database), or [run on dictionary], which takes you to the Dictionary PhoMo page and inserts your ruleset there.
- Rulesets are language-specific, that is, you can have completely different sets for each one of your languages.
- You can have multiple different rulesets per language. For example, I usually have a Rewrite Rules set, and a 'test' set to, well, test things. For some languages, I also have a diachronic sound changing set.
- This drop-down menu lets you choose between PhoMo rulesets that you have already named and used. In the second image, the loaded ruleset is *Rewrite Rules*, which works with the site's Pronunciation Estimation feature.
- Name/Save sets
- Rulesets are named and saved when you hit 'Apply rules & Save Changes'. If you leave the page without hitting that button, any changes you make will be erased.
- 'Save set on run' means that the ruleset will be saved to the database when you hit 'Apply rules & Save Changes'.
- 'New set' makes a new set when you hit 'Apply rules'. It will prompt you to name it.
- 'Don't save' allows you to run the ruleset without saving it to the database. This can be useful for experimenting, but don't forget to eventually either save the differences (by selecting 'Save set on run') or discard them (by navigating away from the page — when you return next, your last saved set will be there).
- Rulesets are named and saved when you hit 'Apply rules & Save Changes'. If you leave the page without hitting that button, any changes you make will be erased.
- Troubleshooting options
- You can toggle these individually and use them to find the problems in your ruleset (why it isn't doing what you want it to do).
- For what each option does in more detail, see the 'Troubleshooting' section below.
- You can toggle these individually and use them to find the problems in your ruleset (why it isn't doing what you want it to do).
- Categories panel
- This panel displays your currently loaded Categories
- This determined by Scope (either General, IPA, or Testing)
- Each ruleset has its own Scope choice saved as a setting
- You can click the displayed Scope ('general' or 'ipa') to switch to the other, or toggle the Testing setting to use those instead
- This determined by Scope (either General, IPA, or Testing)
- You cannot edit your Categories directly from the PhoMo page; follow the handy [edit] link instead
- After updating your Categories, you may need to run your Ruleset twice before the changes register.
- This panel displays your currently loaded Categories
- Ruleset textbox
- This is where the magic happens.
- Insert your code (as explained in the Reading/Writing PhoMo Rules sections of this article) in the box
- You can visit the PhoMo Wizard at [wizard] — this will build some simple rules for you
- Insert one rule per line
- Remember that rules apply in the order they are written (top-to-bottom)
- This is where the magic happens.
- Input textbox
- This is where you put the words you want to change
- (On the PhoMo page, this will often just be for testing purposes)
- Words (which the rules apply to individually) are delineated by spaces or line breaks
- Make sure that if you are using an IPA Scope set, your Input is written in IPA
- Likewise, if you are using a General scope set, your Input should be written in your orthography
- Words (which the rules apply to individually) are delineated by spaces or line breaks
- You can use the "'Input' auto-filler" to select a part of speech and class (if applicable), and CWS will automatically load some of those words into the box as your Input
- The auto-filler can fill General/Orthography (▲) or IPA (æ). It seems a bit buggy though.
- This is where you put the words you want to change
- Apply rules & Save Changes
- This button makes your ruleset run, with the settings you have selected in above sections
- Unless you have clicked the 'Don't save' radio button, it will also save this ruleset to the database
- This button makes your ruleset run, with the settings you have selected in above sections
- Grammar table cell editor
- This will only appear after you have created a Grammar Table (see a tutorial here)
- You will be able to select any table, and any cell from it, and load those rules into your Ruleset box by hitting (▲)
- Be careful to only do this on a blank/new/testing ruleset — it can overwrite others
- You can then use PhoMo as usual, changing the code and hitting 'Apply rules & Save Changes' to see it working with your Input
- Once satisfied, hit ✔ in order to change the table cell to match your current Ruleset
- This will only appear after you have created a Grammar Table (see a tutorial here)
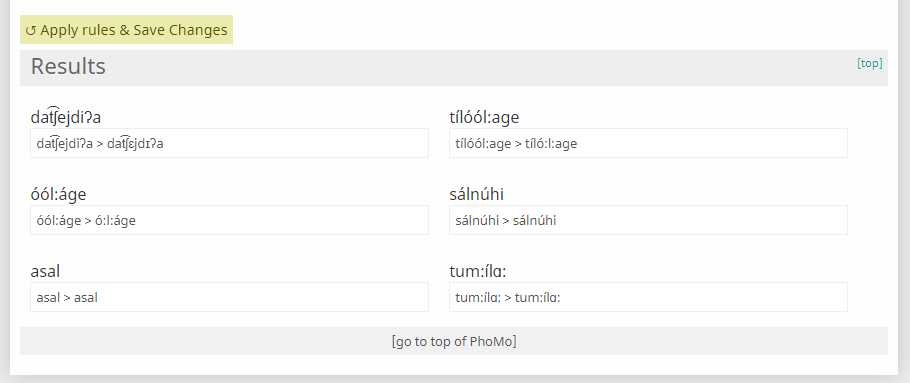
PhoMo Output
After hitting 'Apply rules & Save Changes', your Ruleset will run on your Input, and the Results or output will be displayed below, like so:
Besides the PhoMo page itself, you can also use PhoMo rules on the Pronunciation Estimation page, and within the code cell for Grammar tables. Both have Ruleset textboxes that work identically to that on the PhoMo Page. The Scope is automatically selected on these pages (IPA for Pron.Est., and General for Tables).
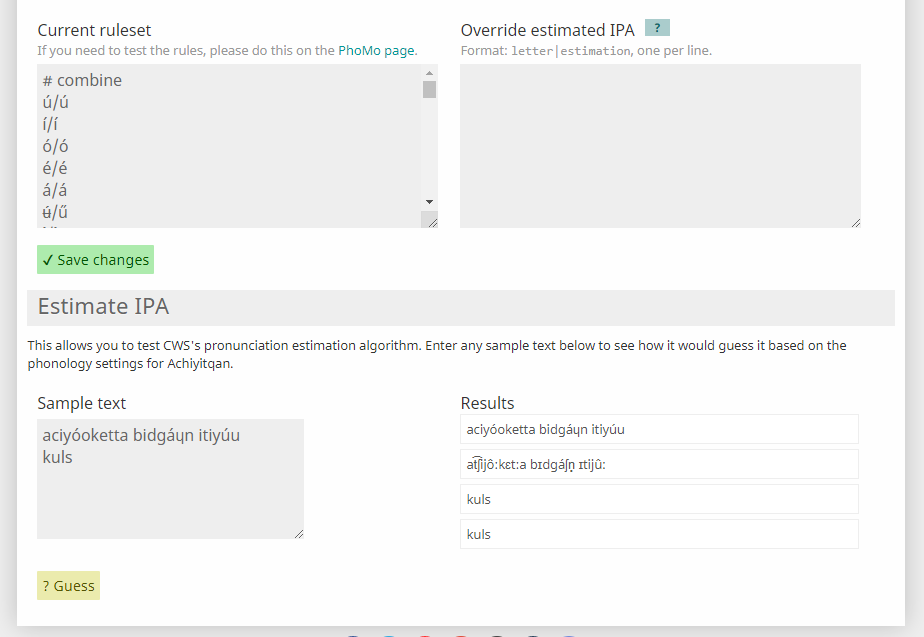
The Pronunciation Estimation page (pictured above) holds the *Rewrite Rules* Ruleset in its 'Current Ruleset' box. You can edit this ruleset from here or the PhoMo page, and the changes should save for both locations. (There are sometimes issues with this though, so double-check that everything is right before running it.)
The 'Override estimated IPA' box allows you force PhoMo to recognize a grapheme as having a different value than it is registered to in your Phonology page. This can be useful for letters that are usually silent (and were therefore added as a Zero sound), or which behave particularly unusually.
Unlike in PhoMo, your input (called 'Sample text') will be in your orthography, and will be translated into IPA and then have the *Rewrite Rules* applied to it.
[top]Troubleshooting options
This section explains how to use the built-in troubleshooting and log options: Track Changes, Show Errors, and Show Full Logs. For more specific troublehsooting and other help, please head to the PhoMo Help Centre.
There are a lot of things that can go wrong in PhoMo, both in terms of users making mistakes, and the site having some sort of malfunction or coding oversight. In order to fix your issue, this is the first thing you have to figure out; thankfully, PhoMo has some built-in tools to help.
The simplest is the Show errors option. With this selected, the site will report any parsing rules from yours set. These can be a bit hard to understand, so you might want help from the forums. Note that this will not stop PhoMo from trying to run, or partially running, your ruleset.
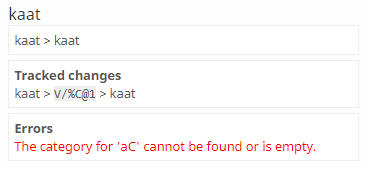
PhoMo doesn't like the %C combination here.
Track changes will show your word go through each rule and the step-by-step changes (or lack thereof) that happen to it throughout the ruleset. This helps you locate which rules are causing undesirable changes; you can then edit that rule, or move it earlier or later in the ruleset to result in the desired output.
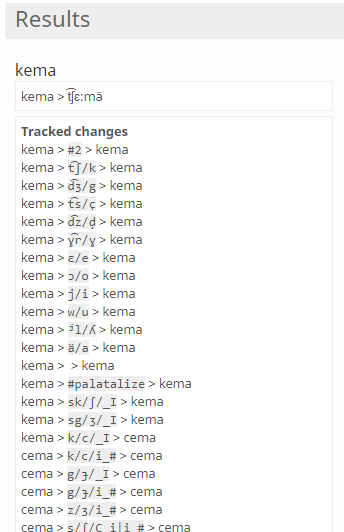
A section of the Tracked Changes output for one of my conlangs.
Show full logs will give you an extremely long
A section of the Full Logs output for the same ruleset
[top]Reading PhoMo Rules
Before you can learn to write PhoMo rules, it might help to be able to read them.
PhoMo code is quite simple, although it can be confusing at first (and there are some more complex/ 'advanced' codes that look pretty intense). Each rule within a Ruleset should appear on a separate line, and use the following structure:
TRG/CHG/ENV/EXP/ELS
The 'environment' and 'exception' segments will be referred to collectively as the 'condition' (COND) when facts are relevant to both. In turn, CHG and ELS can be paired as 'results' (RES) in many instances.
A PhoMo rule means this: "Take the target, turn it into the change, but only if the environment is applicable; if the exception is applicable, turn the target into else instead." For example, you could make a rule like "turn /n/ (TRG) into [m] (CHG) before [b] (ENV), unless it is at the beginning of a word (EXP), in which case add an [a] (ELS) after it." The goal would be to take words like anba, kitanb, inbit and turn them into amba, kitamb, imbit, but words like nbita, nberok would become nabita, naberok instead of mbita, mberok. This rule would be written like this: n/m/_b/#_/%a.
Of course, codes can be much simpler than this. First off, only the TRG and CHG are actually required for a rule to run. So, you could have something as simple as nb/m 'turn all instances of /nb/ into [m].' It can then optionally have one of the conditions, or both, after which you could use ELS. (You can technically have ELS without conditions, but it won't actually do anything.)
You will also see the following symbols, or operators, used in PhoMo code: , # _ % @ ? ^ > = | " !. Each performs a different function. Specific operators may be constrained to different segments, or have (slightly) different meanings depending on where they appear. (This will be explained in greater detail in the 'Writing' section.) As a general rule, the condition segments both use the same operators, the result segments use a different set, and the target segment is unique.
- , (comma) is used to delimit lists (temporary categories), and can only occur in TRG or RES
- # indicates 'the whole word' in TRG and RES, and can mean 'the whole word' or 'the edge of a word' within COND (see Global vs Local conditions in the Writing section)
- _ indicates 'the [location of] TRG'
- % specifies 'something identical to TRG'
- @ specifies an index (numerical placement within the word)
- ? reverses the target (ma→am)
- ^ is used to specify a length, and is limited to RES
- > is used to indicate movement, and is limited to RES
- = is used to specify the quantity of something, and is limited to COND
- | is used as an 'or' — to list multiple conditions
- " ('ditto') makes a rule apply only if the previous rule's ENV was true
- ! is used to escape other characters
(How to use these operators will be described in the 'Writing' section.)
'Emptiness' can also be considered an operator. (Technically, all segments exist in all rules, but they can be empty.) Ending segments can simply be left out of the code altogether (e.g. a/b has no COND, EXP or ELS) ; you can also 'skip' segments by writing a / with nothing before it (since the previous segment). For instance, a/b//c has an exception, but no environment. /c/_b has no targetagain, it still technically has a TRG segment, which happens to be nothingness. Emptiness has different meanings in different segments; in TRG and RES, it means 'null' (used for insertion and deletion) and in COND, it means 'do nothing for this step.'
[top]Writing PhoMo Rules
and now, what you've all been waiting for...
Affix rule basics
We'll start with something easy: simple affix rules. These are used to add prefixes or suffixes to a word. (You can also add both at once (a circumfix!). Infixes and epenthesis are more complicated and will be dealt with later.) These are probably the main type of rule you will use in your Grammar Tables. In affix rules, the TRG must be #. The CHG (and ELS, if applicable) must also contain #. In affix rules, # represents 'the whole word/the word itself.'
To add a prefix, you simply use #/[affix]#. This means, "add the affix to the beginning of the word." So, with the input alles and the rule #/f#, PhoMo will give you the output of falles. Likewise, to make a suffix, #/#zi means "add /zi/ to the end of the word."
Test it out: If your input is tave, and your code is #/#zi, what is your output?
↺
What's the code for circumfixing am- -la around a word?
↺
Replace rule basics
Replace rules are used to transform TRG into CHG.
As above, put TRG at the beginning of the rule, followed by CHG. For example, p/q means 'turn p into q,' and #/nope means 'turn the whole word into nope.' With the input paffa, these rules would produce qaffa and nope respectively. If they were in the same set, and ordered #/nope, q/p, the final result would be noqe.
What would pa/po do to the input apapepo?
↺
What about a/o/p_ to apataka?
↺
Basic deletion rules
In order to delete something, you simply use a replace rule with the RES set to null (blank). For example, p/ will delete all 'p' in the word; n//_t would change yantama into yatama; and ə//_# [note]more about this usage of # in 'Global vs Local conditions' will delete word-final schwa.
What would i//s_s do to simisis ?
↺
What would C//#_ do to simisis?
↺
Is my rule an affix or replace rule?
Most of the time you probably won't care about this, but it's helpful to keep in mind when going through this article or troubleshooting issues in your code.
The difference is this simple: affix rules have # in both TRG and RES; replace rules can have # or something else in TRG, and don't have it in RES. Both can have # in COND.
For each of the following rules, select whether they are Affix or Replace rules.
#/pe ↺
#/#a/#C ↺
V//VC_CV ↺
u/i/i# ↺
V/%$@-1 ↺
#/##@4^2 ↺
Using Categories in PhoMo rules
You can use Categories in any segment of a replace rule. If you have a category P that contains your voiceless stops (p,t,c,k,q), and a category B that contains your voiced stops (b,d,ɟ,g,ɢ), you can use one rule P/B/V_V to apply a voicing rule to all plosives between vowels (instead of five separate ones — p/b/V_V, t/d/V_V, etcor even more if your vowels aren't in a category either, yikes). P/B/V_V will turn aka, ata, apa into aga, ada, aba.
The ordering and number of the characters within the Category matters. For example, if you used the above rule, but your P and B categories were 'misaligned' (e.g. {p,t,k} {g,b,d}), you would get aka, ata, apa → ada, aba, aga. So, make certain to align them as you want them to behave. Also, if one of your Categories has fewer phones than the other, it will result in deletion (e.g. P=p,t,c,k,q ; B=b,d,g ; apa, aka → aba, aa). You can solve this by repeating letters (B=b,d,d,g,g — if you want ɟ,q to become d,g).
You can also use temporary categories. These can occur in the target and result segments. They can be useful if you know you won't be using this 'set' of letters very often. For example, if I want to apply the above voicing rule, but I want (c,q) to remain unchanged instead of becoming (d,g), and I usually want B to only contain (b,d,g), I could use a temporary category as my CHG instead: P/b,d,c,g,q/V_V.
In affix rules, you can only use Categories in COND. We've seen this a few times already, with the ENV V_V ("between vowels"). You can't use them in TRG or RES of an affix rule — P/#t and #/#B won't work, because they are meaningless to PhoMo.
Which of these Category sets will get kapoti to become kabodi ?
↺
With the Categories E=i,e,æ and O=u,o,ɑ, what will O/E/j_ do to kijoju ?
↺
With the same Categories, what will #/#E/#O do to kijoju?
↺ The final part of this rule reads "If the word begins with O.
Global vs Local conditions
The COND segments can either show 'global' or 'local' conditions. Global conditions affect all instances of TRG within a word depending on the word's overall content; local conditions may only apply to one or two instances of TRG, depending on their exact COND or placement within the word.
There are only five global conditions. The first three check whether the word starts with, ends with, or contains (any number of) some specified entity. For example, #f means 'if the word ends with /f/' ; O# means 'if the word begins with category O' ; and p means 'if the word contains at least one /p/.' So, #/#s/#V will suffix -s, but only if the word already ends in a vowel. U/Ü/I will turn all instances of U (u,o,a) into Ü (ü,ö,ä) if the word already contains any I (i,e).
Next is the 'count condition,' which uses the operator = to test exactly how many instances of an entity occur in the word; it can also have 'less than' or 'greater than' function (=<. e=3 means "if the word contains 3 instances of [e]." U/Ü/I=>2 turns all instances of U into Ü only if there are 2 or more instances of I in the word.
The final global condition is then the 'ditto' condition, which uses ", and means that a rule will only apply if the previous rule also successfully met its ENV. For example, the rule sequence #/#w/#V, #/#at/"//#ut means "suffix -w if the word ends in a vowel; now, if a -w was just added, also suffix -at. If -w was not just added, suffix -ut instead." This would turn apa, pak, paw into apawat, pakut, pawut (the /w/ in pawut wasn't added by the rule, but is part of its stem, so it takes the normal suffix, -at). (You could also perform this particular change in one rule#/#wat/#V//#ut "suffix -wat if the word ends in a vowel; otherwise (AKA if it ends in a consonant), suffix -ut".)
There is technically only one local condition, although it can be very complex. It can only occur with replace rules, not affix rules. It is indicated using the _ (underscore) operator, which 'stands in place of' the TRG, relative to some specific trigger (usually an immediately adjacent sound). The placement of the underscore indicates whether the TRG appears before or after the conditioning entity; for example, a/æ/j_ reads "turn /a/ into [æ] after [j]." This would change aja into ajæ, while a/æ/_j "turn /a/ into [æ] before [j]" does the inverse, changing aja into æja.
The local condition can also contain #, although it uses it somewhat differently than in all other rule segments. While in affix rules and global conditions it represents 'the word itself,' in local conditions # represents 'the word edge' (which makes it, in effect, reversed). So, while the global COND t# means 'if the word begins with /t/', _# means 'if TRG is at the end of the word.' E.g. p/b/#_ "turn /p/ into /b/ at the beginning of the word" vs p/b/#V "turn all instances of /p/ into /b/ if the word ends in a vowel."
How could you prefix ki- before /p/, but just k- before /a/?
↺ (Remember: the 'exception' goes before the 'else'.)
How could you change pinim to finim ?
↺
This actually has a lot of possible answers. If you got marked wrong, but it still works when you try it in PhoMo, that's fine!
How do you change all /s/ to /ʃ/ before /i/, but not if the /s/ is after /u/ ?
↺
How can you suffix -s most of the time, but -ʃ after category I (i,ɪ,j) ?
↺
How would you delete all word-final /ə/ ? (Remember: in COND, # represents "the word edge", not "the word itself".)
↺
Instancing and indexing (@)
The @ operator belongs within RES. With replace rules it is used to specify an instance of a character or category (e.g. the third /i/ or the last V), and with affix rules it can be used to refer to an index within the word (e.g. the third space - between the 3rd and 4th letters). Again, this must occur within RES, so g/k@3 turns the third instance of /g/ into [k] while the more obvious-seeming g@3/k or g/k/@3 do not.
You count from the right edge (end) of the word by putting - before the number. Note that it begins counting from -0, not -1.
What would #/@3 do to simisis?
↺
What would #/h@-3 do to simisis?
↺
How could you change the 2nd vowel in a word to ə?
↺
Spans (^)
Using ^ before a number lets you select a number of letters to modify. For example, you might want to delete the last 3 letters, instead of just one. Spans are usually used in conjunction with indexes (see above). Spans are used in the COND section, generally appearing immediately after an instance/index, so you will see strings like @1^3 ("the first three letters") or @-5^4 ("four letters starting at index -5"). Spans cannot be negative numbers. Spans are mostly used for deletion, reduplication, and movement.
Note that spans at the end of the word aren't counted 'in reverse.' So @-1^3 will select three letters starting from -1 and counting to the right — so that will actually only be the last letter. To delete the last three letters, you will need to set your index to -3 as well.
How would you delete the last 3 letters of a word?
↺
What will #/@-1^17 do to tambur?
↺
Movement
Movement is an 'affix' rule which can contain three numbers: a destination, a source, and (optionally) a span. The code is built like this: #/>index@index^span, with the first index being the source, and the second the destination. So, #/>1@3 will move the first character to the third place (e.g. katepi → atkepi).
The span (^) value can be used to move more than one character. So, #/>1@3^2 will move the first two characters to the third position (katepi → takepi).
Please note that this rule type does not work 100% as intended. The 'destination' index starts counting from index 0, not index 1, but also will not accept 0 as an index. This means that that you cannot use these rules to move something to the very first position. (As a workaround, perform the move to the 'first position' (second position) (e.g. #/>4@1), and then use a reversal rule to swap the first and second characters: #/?1^2 ; or use another 'move' operation to move the undisplaced first-place character to its intended new position (e.g. fourth)).
Reduplication and copying
Reduplication is the process of taking a whole word, or the end of it, and repeating it at the end. To reduplicate a whole word, simply use #/##. To reduplicate only part of a word, you'll need an index and a span; for example, #/##@-2^2 will reduplicate the last two sounds (e.g. taku → takuku). This only works to duplicate to the end of the word, however.
In order to copy a segment — or, really, to move a segment without deleting the original segment — use a move rule (see above) with an exclamation mark ! after the move operator >. For example, #/>!1@3 copies the first character to the third position (e.g. katepi → katkepi). You can again use this with a span (^). As with the basic move operator, there are some parts of this rule that do not work 100% as intended; so while #/>!1@3^2 should copy the first two characters to, in theory, the third position, in practice, it moves it to the fourth: katepi → katekapi ; with 1@3^3 we get katepkati.
As with the plain move rule, the copy rule will not correctly move segments to the first position.
Using Replace rules to affix
You can use replace rules to affix things to a word to circumvent some of the limitations of Local Conditions (see above). This can't do quite all of the things a real affix rule can do, but it can do some.
There are two methods: using % ('same as TRG') or using a null (empty) TRG. For example, you could insert schwa between all consonant clusters with C/%ə/_C ("replace C with itself+schwa before another C") or /ə/C_C ("insert schwa between two Cs"). When things get a little more complicated, the first option wins out: C/%ə@-1/_C only breaks up the last consonant cluster in the word. (If you wanted to break up, say, the last two clusters, you could simply repeat the rule in your set.)
Multistep Rules
Often you need more than one PhoMo rule to perform a single sound change. Sometimes these are fairly straightforwards: change thing 1, change thing 2. They can be much more complicated, however. Always keep in mind that rules always apply in order (from the top to the bottom of the ruleset).
Here's a straightforward 'feed' (the first rule creates environments for, or 'feeds', the second): Say you want to "nasalize a vowel before a word-final nasal, and then delete that nasal (but not other nasals)." Using the categories N=n,m,ŋ, V=i,e,a,o,u, and Ṽ=ĩ,ẽ,ã,õ,ũ, you can do this: V/Ṽ/_N#, then N//Ṽ_#. (If you left the Ṽ out of the second rule, it would delete all word-final nasal stops, even if the first rule hadn't applied.) If you reversed the order of these rules, you might not delete any Ns (depending how many Ṽ your language already has).
The ditto operator " mentioned above can only be used in multistep rules. Its effects can also often be met with a single rule using all five rule segments; however, there are some cases where ditto is the only way to achieve something.
Sometimes simply repeating a rule can be useful. For instance, most rules that affect specific instances only affect one instance (e.g. the first C in a word), but if you want it to affect multiple instances (i.e. the first two or three voiceless plosives), just copy+paste the exact same rule below the first one. (e.g. P/B/@1 changes pakata → bakata ; if it is repeated, then → bagata.)
The last important technique for multistep rules is the use of placeholders. Most frequently, placeholders are used as part of a sort of complex exception, e.g. b/$, B/P/_#, $/b "turn /b/ into $, turn voiced stops voiceless at the end of a word, turn $ into /b/" is essentially the same as "devoice word-final stops — except for /b/."
A placeholder can be any character that A) isn't a PhoMo operator (like #, ?, =) or other character that PhoMo just doesn't like (avoid apostrophes), and B) doesn't already occur in your language. If you use capital letters for this purpose, be sure to precede them with ! (e.g. b/!B) or else PhoMo will think you are referencing a Category (that might not even exist). In this article I'll use $.
[top]Examples: How do I...?
This section will give loads of examples, but won't generally explain how or why they work. To figure that out, see the above sections.
These examples will all follow the same format:
phomo code input → output ; additional → examples...
= will be used instead of → when there is no actual change based on the rules. $ will be used for placeholders.
All rules will assume the following Categories:
V = a,e,i,o,u
Á = á,é,í,ó,ú
À = à,è,ì,ò,ù
C = (all consonants)
N = n,m,ŋ
P = p,t,k
B = b,d,g
I = i,e,j
Use capital letters as phones instead of Categories, or use special characters instead of Operators. Insert ! before the letter wherever it appears in your rules. (Note that this will not always work with Operators. It is advised that you do not use them in your orthography.)
P/!B/V_V + potato → poBaBo
!B/p/_o + poBaBo → poBapo
!-/s/_I + pa-i → pasi
Don't change anything. Write nothing, or #/#. Useful for zero-marked or uninflected Grammar forms.
#/# + potato = potato
Replace an entire word. Set TRG to # and RES to the new word. Useful for suppletive Grammar forms.
#/mia + mama → mia
Delete an entire word. Set TRG to # and RES to blank.
#/ + lamb → [nothing]
Delete (all instances of) X. Set the RES to blank.
m/ + mamama → aaa
mb/ + lamb → la
Delete X at the beginning/end of a word.
C//#_ + matat → atat
C//_# + matat → mata
Delete X before/after Y.
b//m_ + lamb → lam
m//_b + lamb → lab
Delete X before/after Y at the beginning/end of a word.
m//_b# + mbambamb → mbambab
b//#m_ + mbambamb → mambamb
m//#_b + mbambamb → bambamb
Delete nth instance of X. Set RES to @[instance].
m/@1 + mamamb → amamb
m/@2 + mamamb → maamb
m/@-1 + mamamb → mamab
m/@-3 + mamamb → amamb
Delete X before/after itself.
C//_% + atta → ata
Delete part of a word. Set TRG to # and RES to @[index]^[span].
#/@1^4 + mikmambu → ambu
#/@2^4 + mikmambu → mmbu
#/@-2^2 + mikmambu → mikmam
Delete whatever is at the beginning/end of a word, or at position n.
*//#_ + satu → atu ; alas → las
*/@2 + satu → stu ; alas → aas
Suffix something. Set TRG to # and begin RES with #.
#/#m + sa → sam ; sad → sadm
#/#m/#V + sa → sam ; sad = sad
Prefix something. Set TRG to # and end RES with #.
#/m# + at → mat ; dat → mdat
#/m#//C# + at → mat ; dat = dat
Circumfix something. Set TRG to # and put # in the middle of RES.
#/p#o + tat → potato
Affix something different depending on the stem.
#/#m/#V//#im + sa → sam ; sad → sadim
#/m#/V#//mi# + at → mat ; dat → midat
#/#u/u/i/#ü + tukat → tukatu ; tikat → tikatü
Affix something while changing the stem. You'll need two rules. Order them carefully.
b/p/_#
#/#t + abab → abapt
e/i/#_
#/s# + elen → silen
#/i#
u/ü/i# + tulu → itülü
u/ü/i#
#/i# + tulu ⇒ itulu
Insert X before/after Y or between Y & Z.
/ˀ/t_ + gati → gatˀi
/:/_t + gati → ga:ti
/s/t_i + gati → gatsi
Insert X before/after position n. Set TRG to # and RES to X#@[index]. To 'insert' at the beginning or end of the word, it's much easier to use the prefix/suffix rules described above.
#/a#@2 + tutu → tautu
#/#a@2 + tutu → tuatu
#/n#@-1 + tutu → tutnu
#/n#@-2 + tutu → tuntu
Insert X before nth instance of Y. Set COND to [affix]%@[instance]. Useful for infixes or marking.
V/k%@1 + tahama → tkahama
V/k%@-1 + tahama → tahamka
Insert X after nth instance of Y. Set COND to %[affix]@[instance]. Useful for infixes or marking.
V/%k@1 + tahama → takhama
V/%k@-2 + tahama → tahakma
Insert X between identical Ys. Useful for epenthesis. Set TRG to Y and RES to %X.
V/%ʔ/_% + kaat → kaʔat
C/%ə/_% + atta → atəta
Change X before/after Y.
a/o/p_ + apa → apo
a/o/_p + apa → opa
a/o/p_p + apapa → apopa
s/ʃ/_I + sisasju → ʃisaʃju
z/s/_CC + azprizta → asprizta
Change X at the beginning or end of a word. Use # to mark the word boundary.
g/k/_# + kelag → kelak
k/h/#_ + kelak → helak
Change X before/after Y at the beginning/end of a word.
s/z/V_# + atas → ataz ; ats = ats
a/á/#h_ + hasa → hása
a/á/#_h + ahsa → áhsa
Change X before/after itself.
C/:/%_ + akka → ak:a
C/:/_% + akka → a:ka
Change X between identical Ys. You'll need three steps for this. First, set TRG to Y and mark X with a placeholder. Then change X based on the placeholder's presence.
V/%$/_s%
s/θ/$_
$/ + casa → caθa ; casi = casi
Change X before/after a category.
P/:/P_ + apka → ap:a
V/:/V_ + asae → asa:
B/P/_P + abka → apka
Change X based on far away Y. Use the * operator to mean "any number of letters here". Useful for vowel harmony. NOTE: * is notoriously temperamental and will just not work sometimes. Sorry.
u/ü/i*_ + pukaliku → pukalikü
u/ü/_*i + pukaliku → pükaliku
Change X based on the word's beginning or end.
u/ü/i# + pukaliku = pukaliku ; ipukaliku → ipükalikü
u/ü/#i + pukaliku = pukaliku ; pukalikuti → pükaliküti
Change X if word contains n (or more/less) instances of Y. Use equals, lesser than, greater than signs in COND.
u/ü/i + pukaliku → pükalikü ; pukalaku = pukalaku
u/ü/i=2 + ipukaliku → ipükalikü ; ipukalikuti = ipukalikuti
u/ü/i=>2 + ipukaliku → ipükalikü ; ipukilikutikiti → ipükilikütikiti
u/ü/i=<2 + ipukaliku = ipukaliku ; ipukaluku → ipükalükü
Change nth instance of X to Y. Set RES to Y@[instance].
V/Á@1 + yutukalahs → yútukalahs
a/á@1 + yutukalahs → yutukálahs
V/À@-1 + yutukalahs → yutukalàhs
Change nth instance of X to Y, but only if it is the nth member of its category. Use three steps with a placeholder. Firstly, set TRG to X and RES to %$@[instance]. Then apply your changes using the placeholder in COND.
V/%$@-1
a/á/_$
$/ + yutukalahs → yutukaláhs
V/%$@-1
u/ú_$
$/ + yutukalahs = yutukalahs
Change X at position n. Use three steps and a placeholder. Firstly, set TRG to # and RES to #$@[index]. Then apply your changes using the placeholder in COND.
#/#$@4
P/B/_$
$/ + atape → atabe ; + tape = tape
#/#$@-2
P/B/_$
$/ + atape → atabe; + tape → tabe
Reduplicate word. Set TRG to # and RES to ##.
#/## + sa → sasa ; + mikmambu → mikmambumikmambu
Reduplicate words of a certain size.
#/##/*=2 + ta → tata ; + tak = tak
#/##/*=<4 + ta → tata ; + tak → taktak ; + taka = taka
Reduplicate part of a word. Set TRG to # and RES to ##@[index]^[span].
#/##@1^2 + mikmambu → mimikmambu
#/##@1^3 + mikmambu → mikmikmambu
#/##@-1^2 + mikmambu → mikmambuu [note]PhoMo is counting from LTR starting at -1, so a span of 2 is u[nothing].
#/##@-2^2 + mikmambu → mikmambubu
#/##@2^2 + samit → samamit
#/##@3^2 + samit → samimit
#/##@4^2 + samit → samitit
#/##@2^4 + samit → samitamit
Copy nth X to the end/beginning of the word. Set TRG to # and RES to #X@[instance]
#/#C@2 + palu → palul ; tasi → tasis
#/V@-1# + palu → upalu ; tasi → itasi
#/C@1#/V# palu = palu ; ipalu → pipalu
Copy nth X to position n². Use three rules and a placeholder. Firstly, set TRG to X and RES to %$%$@[instance]. Then move your duplicated item using >$_$@[index].
C/%$%$@2
#/>$_$@-1
$/ katiru → katirut
V/%$%$@-1
#/>$_$@2
$/ katiru → kautiru
Move part of a word using indices. Set TRG to # and RES to [index]@[index]^[span].
#/>1@3^2 + mikmambu → kmmiambu
#/>-2@+0^2 + mikmambu → bumikmam
Reverse part of a word. Set TRG to # and RES to ?[index]^[span].
#/?-2^2 + mikmambu → mikmamub
#/?-4^2 + mikmambu → mikmmabu
Adding a separate word. Use - instead of a space.
#/#-na + ke → ke na
Splitting a word. Set TRG to # and COND to #-@[index].
#/#-@3 + mikmambu → mik mambu
#/#-@-3 + mikmambu → mikmam bu
Have multiple conditions. Use the | operator.
a/o/p_|_p + apate → opote
a//#_CV|VC_#|VC_CV + atalata → tlta [bleed]when the first condition triggers, it erases the environment of the second one, so only the first condition is triggered
a//#_CV|VC_# + atalata → talat
a//VC_CV|#_CV|VC_# + atalata → taa [bleed + some PhoMo coding issues — split into 2 rules to make this work]
Add vowel harmony.
There are many ways to do this depending on your exact needs. See the examples using input string pukaliku and similar above for some good starting points.
Add liaison between words.
PhoMo stops parsing when it hits a space, so this is not possible for a sequence like "les œufs". However, if you are using - or another character instead of spaces, as in "allons-y", it is possible:
z-/:-/_C + alõz-lə → alõ: lə
z-/z‿/_V + alõz-i → alõz‿i
z-/‿z/_V + lez-œf → le‿zœf
Add syllables and stress. This needs its whole own article. Note that you can use . in your orthography to delimit syllables if you want — this makes assigning stress much easier.
[top]Tips & Tricks
Organizing, sectioning, or commenting your rulesets. If you want to add "sections" or "titles" within a long PhoMo ruleset, it is perfectly find to leave blank lines, or to include "titles" or "comments" — any line without a /, PhoMo will ignore. For example, this is a perfectly functional ruleset:

Here I've started off with some input sanitation such as combining digraphs into monographs (see next tip), followed by a section of palatalization rules, and then some vowel-to-glide rules.
Making it easier to work with digraphs/complex sounds. As explained in their section, Categories do not work well with digraphs. Many other rules are also easier to write when all of the relevant sounds are monographs. There is a straightforwards workaround for this:
- Choose a substitute monograph for each of your digraphs. For example, <ā> for /a:/, <q> for /kʷ/, or <Ḿ> for /ᵐʘ̬ˀ/.
- Make sure it's not a character already used within that Scope, or as a PhoMo Operator (generally: avoid punctuation).
- If you use a capital letter, be sure to escape it with ! (e.g. ᵐʘ̬ˀ/!Ḿ)
- Make sure it's not a character already used within that Scope, or as a PhoMo Operator (generally: avoid punctuation).
- Add the substitute character to your Categories instead of, or as well as, the original one.
- At the beginning of your set, enter a string of substitution rules, changing each digraph into its respective monograph.
- Throughout your ruleset, refer to the substitute, not the actual form.
- You might have to add additional substitute forms during the set — for instance, if you're using <ā> for /a:/, and /a:/ is supposed to become /á:/ after /h/, you might want to use ā/â/h_.
- Add these to your Categories as well.
- You might have to add additional substitute forms during the set — for instance, if you're using <ā> for /a:/, and /a:/ is supposed to become /á:/ after /h/, you might want to use ā/â/h_.
- At the very end of your ruleset, replace all substitutes with their correct forms.
Comments

Edit history
on 07/05/20 18:490[Deactivated User]typo
on 08/09/19 23:32+13109[Deactivated User]please do not edit the WHOLE article or it will erase parts of the last few sections which are over the character limit whoops





